The Extended PyMARL Codebase for Multi-Agent Reinforcement Learning

Motivation
Extended PyMARL (EPyMARL) is a codebase written in Python for training cooperative Multi-Agent Deep Reinforcement Learning (MARL) algorithms. EPyMARL extends the PyMARL codebase which includes several MARL algorithms, such as IQL, COMA, VDN, QMIX and QTRAN; however, the original PyMARL implementation is only compatible with the StarCraft Multi-Agent Challenge [6] and many of the implementation details in PyMARL are fixed, and cannot be easily altered. For example, in PyMARL, all parameters are shared among the agents, the first layer of the policy network is a RNN, and hard updates are used for the target networks. As part of our NeurIPS 2021 benchmark paper [5], we open-sourced the EPyMARL codebase which extends PyMARL to add compatibility with OpenAI Gym, include additional algorithms (IA2C, IPPO, MADDPG, MAA2C, MAPPO), provide more flexibility with algorithm implementation details (e.g. options for no-parameter sharing, hard/soft updates, reward standardisation), and include code for hyperparameter sweeping. This blog post provides a description of the EPyMARL codebase, how to install it and run experiments, and how to use it to implement new MARL algorithms.
Multi-Agent Reinforcement Learning Algorithms
We consider an environment that contains several agents that need to cooperate to achieve a goal (formalised as a Dec-POMDP). At each time step, each agent has access to a partial observation of the environment, and each agent takes an action based on the history of its observations, according to its behavioural policy. The environment receives the joint action (the actions of all agents) and gives a new observation to each agent, and a single scalar reward shared among all agents. The goal of cooperative MARL is to compute the policy for each agent which maximises the expected sum of discounted rewards for the duration of the episode.
In our paper [5], we implemented and evaluated nine commonly used MARL algorithms. Each algorithm belongs to one of the three following categories.
Independent Learning Algorithms
In this category, each agent is trained independently, ignoring the presence of other agents in the environment. In this category, we have three algorithms:- Independent Q-Learning (IQL): In IQL [10], each agent is trained using the DQN algorithm, based on its trajectory.
- Independent Advantage Actor-Critic (IA2C): In IA2C, each agent is trained using the A2C algorithm [2], based on its trajectory.
- Independent Proximal Policy Optimisation (IPPO): In IPPO, each agent is trained using the PPO algorithm [7], based on its trajectory.
Centralised Policy Gradient Algorithms
This category includes actor-critic algorithms in which the actor is decentralised (conditioned only on the trajectory of each agent), while the critic is centralised and computes either the joint state value function (V value) or the joint state-action value function (Q value) conditioned on the joint trajectory of all agents. In this category, we have four algorithms:- Multi-Agent Deep Deterministic Policy Gradient (MADDPG): MADDPG [4] is the multi-agent version of the DDPG algorithm [3], where the critic is trained centralised to approximate the joint state-action value.
- Counterfactual Multi-Agent Policy Gradient (COMA): COMA [1] is an actor-critic algorithm, where the critic computes a centralised state-action value function. The major contribution of COMA compared to vanilla actor-critic is that it uses a modified advantage estimation that allows for credit assignment based on the shared reward.
- Multi-Agent Advantage Actor-Critic (MAA2C): MAA2C is a multi-agent version of the A2C algorithm, where the critic is a centrally-trained state value function conditioned on the joint trajectory of all agents.
- Multi-Agent Proximal Policy Optimisation (MAPPO): MAPPO [11] is a multi-agent version of the PPO algorithm, where the critic is a centrally-trained state value function conditioned on the joint trajectory of all agents.
Value Decomposition Algorithms
Algorithms in this category try to decompose the shared reward that the agents receive into individual utilities based on the contribution of each agent. In this category, we have two algorithms:- Value Decomposition Networks (VDN): VDN [8] is an algorithm based on IQL. Each agent has a network that approximates its Q-values. The Q-values of all agents are summed together to compute the Q-value of the joint action. The Q-value of the joint action is trained using the standard Q-learning algorithm.
- QMIX: QMIX [9] is another value decomposition algorithm that, instead of summing the individual Q-values, uses a mixing neural network with learnable parameters to approximate the Q-value of the joint action. This allows for a broader factorisation of the shared reward compared to VDN.
Installation
EPyMARL and PyMARL are written in Python 3. All the experiments in our paper [5] were executed with Python ≥3.7. Before installing any of the EPyMARL dependencies, we recommend creating a Conda or a virtual environment. The EPyMARL dependencies can be installed by executing the following commands in a terminal:
git clone https://github.com/uoe-agents/epymarl.git
cd epymarl/
pip install -r requirements.txt
Running Experiments with Gym Environments
In our work [5], we benchmarked the nine aforementioned MARL algorithms in three Gym Environments: Multi-Agent Particle Environment (MPE), Level-Based Foraging (LBF), and Multi-Robot Warehouse (RWARE). To run an experiment in any of these three environments, first, make sure that the environment is installed. You can install the environments using the following GitHub repos:
Level Based Foraging or install with
pip install lbforagingMulti-Robot Warehouse or install with
pip install rwareOur fork of MPE, clone it and install it with
pip install -e .
For MPE, our fork is required for EPyMARL, which fixes some technical issues with the original version of MPE, without changing the environment dynamics. Essentially, all it does (other than fixing some Gym compatibility issues) is (1) register the environments with the Gym interface when imported as a package, (2) correctly seed the environments, and (3) make the action space compatible with Gym.
EPyMARL supports environments that have been registered with Gym. The only difference with the Gym framework would be that the returned rewards should be a tuple (one reward for each agent). In this cooperative framework, we sum these rewards together. Environments that are supported out of the box are the ones that are registered in Gym automatically. Examples are the LBF and the RWARE environments. To register a custom environment with Gym, use the template below (taken from Level-Based Foraging).
from gym.envs.registration import registry, register, make, spec
register(
id="Foraging-8x8-2p-3f-v1", # Environment ID
entry_point="lbforaging.foraging:ForagingEnv", # The entry point for the environment class
kwargs={... # Arguments that go to ForagingEnv's __init__ function
},
)
To run an experiment in a Gym environment, execute the following command
python src/main.py --config=qmix --env-config=gymma with
env_args.time_limit=50 env_args.key="lbforaging:Foraging-10x10-3p-3f-v1"
In the above command:
--configrefers to the config files insrc/config/algs.--env-config=gymmauses the Gym-compatible multi-agent wrapper for cooperative environments (in contrast tosc2for a SMAC Gym compatible wrapper).env_args.time_limit=50sets the maximum episode length to 50 time steps.env_args.key="..."provides the Gym's environment ID. In the ID, thelbforaging:part is the module name (i.e.,import lbforagingwill run automatically).
The config files act as defaults for an algorithm or environment. They are all located in src/config. All results will be stored in the results folder. After running this command for all nine different algorithms and five different runs for each algorithm, we can generate the following figure, which presents the average episodic evaluation returns over the five different runs and the 95% confidence interval.
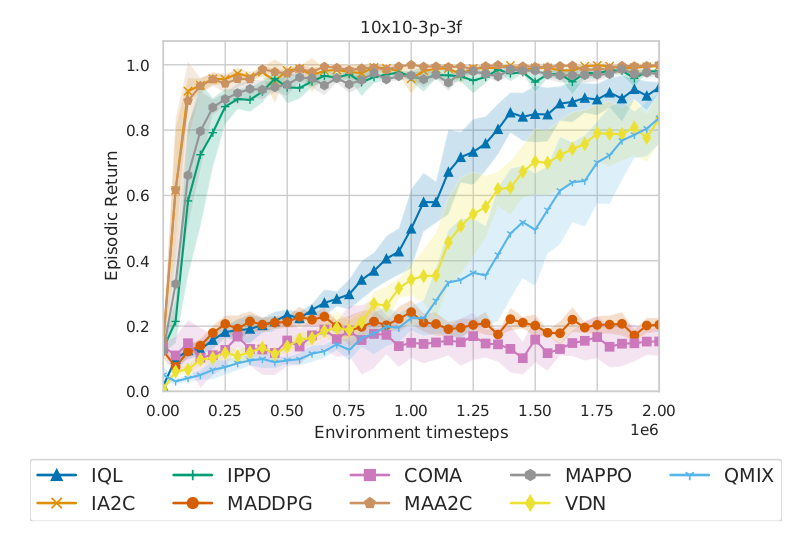
Average evaluation returns over five runs and the 95% confidence interval of the nine MARL algorithms in the lb-foraging 10×10-3p-3f task.
Running a Hyperparameter Search
EPyMARL provides a script named search.py in the src/ folder, which reads a search configuration file (e.g., the included search.config.example.yaml) and runs a hyperparameter search in one or more tasks. The script can be run using:
python search.py run --config=search.config.example.yaml --seeds 5 locally
In a cluster environment where one run should go to a single process, it can also be called in a batch script:
python search.py run --config=search.config.example.yaml --seeds 5 single 1
where the 1 is an index to the particular hyperparameter configuration and can take values from 1 to the number of different combinations. The search.config.example.yaml file contains for each hyperparameter the values that will be searched. The total number of different combinations is the product between the length of the value range of all hyperparameters.
Prototyping with EPyMARL
EPyMARL and PyMARL are large codebases that consist of several files and thousands of lines of code. Therefore, it can be difficult to be used initially for implementing new algorithms. In this section, we describe the basic code structure of EPyMARL and how a new algorithm can be included in the codebase. Below, we present the main folder structure of the EPyMARL codebase.
src
|-- components (basic RL functionalities, such as the experience replay)
|-- config (configuration files)
| |-- algs (for the algorithms)
| |-- envs (for the environments)
|-- controllers (controllers for the action selection pipeline)
|-- envs (environment wrappers)
|-- learners (code for training different algorithms)
|-- modules
| |-- agents (network architecture for the policy networks)
| |-- critics (network architecture for the critic networks)
| |-- mixers (network architecture for the mixing networks)
|-- pretrained
|-- runners (code for the interaction between the agents and the environment)
|-- utils
The agents folder contains the architecture of the network that performs the action selection for the agent. In EPyMARL, we have two different implementations for the network; one with parameters shared among all agents, and one without parameter sharing. Therefore, if we want to try a different network architecture, for example, a transformer-based network, we would just need to implement it inside this folder. It is important to note that the code that is contained in this folder, implements only the construction of the input to the networks and the forward pass. All other class variables, such as the hidden states, are updated by different files.
The controllers folder contains files that implement the full action selection pipeline. The code builds the input vector for the network, updates the hidden states of any RNN if there is one, and performs the action selection policy (e-greedy, greedy and soft). Additionally, it initialises the agent network that is used for the action selection.
The learners folder contains the code that implements the training of all networks. First, it initialises any model that is used only during training (such as a critic or a mixer) in the constructor. Its main functionality is to implement the training of all networks (both the agent networks and the networks that are only used during training). By default, the codebase performs gradient updates at the end of each episode. Therefore, the function train of the learner class receives as input a batch of episodes and implements the computation of all losses (for example both for the actor and the critic) and performs the gradient steps.
The runner folder contains two different implementations for the interaction between the agents and the environment. The first one is the classic implementation of RL, where the agent interacts with a single instance of the environment. The second one implements several parallel instances of the environment, and at each time step, the agents interact with all of these instances.
The components folder has several files that implement basic functionalities of RL, such as an experience replay, different action selection methods (such as e-greedy or soft policies), reward standardisation, etc.
In all the aforementioned folders, there is a part of code (usually inside the __init__.py) where different implementations are registered in a dictionary. For example, in the agents folder the __init__.py file is the following:
REGISTRY = {}
from .rnn_agent import RNNAgent
from .rnn_ns_agent import RNNNSAgent
REGISTRY["rnn"] = RNNAgent
REGISTRY["rnn_ns"] = RNNNSAgent
Let's assume we want to implement a new algorithm, such as a modified architecture for the actor's network. If we implement a new architecture for the agent, we have to register it in this dictionary. For example, consider that we have implemented an attention-based architecture for the agents in the attention_agent.py file. We should now register that new architecture inside the __init__.py file of the agents folder:
REGISTRY = {}
from .rnn_agent import RNNAgent
from .rnn_ns_agent import RNNNSAgent
from .attention_agent import AttentionAgent
REGISTRY["rnn"] = RNNAgent
REGISTRY["rnn_ns"] = RNNNSAgent
REGISTRY["attention"] = AttentionAgent
We have a different dictionary for different modules that are part of algorithms. For example, one dictionary for the agent's network, one dictionary for different types of critics, etc. The keys of these dictionaries are used in the config files to design the algorithm. In the config folder, we have the default.yaml file that contains some default hyperparameters and different modules for the algorithms. Inside the alg folder, we have one config file for each algorithm. All the arguments inside the algorithm config file overwrite the ones that are in the default.yaml file.
For example, consider the IA2C config file:
action_selector: "soft_policies"
mask_before_softmax: True
runner: "parallel"
buffer_size: 10
batch_size_run: 10
batch_size: 10
env_args:
state_last_action: False # critic adds last action internally
# update the target network every {} training steps
target_update_interval_or_tau: 0.01
lr: 0.0005
hidden_dim: 64
obs_agent_id: True
obs_last_action: False
obs_individual_obs: False
# use IA2C
agent_output_type: "pi_logits"
learner: "actor_critic_learner"
agent: "rnn"
entropy_coef: 0.01
standardise_returns: False
standardise_rewards: True
use_rnn: True
q_nstep: 5 # 1 corresponds to normal r + gammaV
critic_type: "ac_critic"
name: "ia2c"
t_max: 20050000
In this file, besides the hyperparameters, we have details about the different modules that are part of the algorithm. For example, the type of policy
is pi_logits that corresponds to a soft policy. The type of actor is rnn, which means that it is an RNN-based network with shared parameters among the agents. By changing this argument to attention, we would end up with an attention-based architecture for the policy network. The type of the critic is ac_critic, which means that the critic is conditioned on the local trajectory of each agent. By changing this argument to cv_critic, we would end up with the MAA2C algorithm, which uses a centralised critic conditioned on the
joint trajectory of all agents. After implementing all components for a new algorithm, a file new_alg.yaml should be created inside the alg folder.
This file will contain all necessary components and hyperparameters of the new algorithm.
Citing EPyMARL
If you use EPyMARL in your work, please cite:@inproceedings{papoudakis2021benchmarking,
title = {Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks},
author = {Georgios Papoudakis and Filippos Christianos and Lukas Schäfer and Stefano V. Albrecht},
booktitle = {Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS)},
year = {2021},
url = {http://arxiv.org/abs/2006.07869},
openreview = {https://openreview.net/forum?id=cIrPX-Sn5n},
code = {https://github.com/uoe-agents/epymarl},
}References
- Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. "Counterfactual Multi-Agent Policy Gradients." AAAI Conference on Artificial Intelligence, 2018.
- Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. "Asynchronous Methods for Deep Reinforcement Learning." International Conference on Machine Learning, 2016.
- Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. "Continuous Control with Deep Reinforcement Learning." International Conference on Learning Representations, 2016.
- Ryan Lowe, Yi I. Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. "Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments." Neural Information Processing Systems, 2017.
- Georgios Papoudakis, Filippos Christianos, Lukas Schäfer, and Stefano V. Albrecht. "Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks." Neural Information Processing Systems Track on Datasets and Benchmarks, 2021.
- Mikayel Samvelyan,Tabish Rashid, Christian Schroeder De Witt, Gregory Farquhar, Nantas Nardelli, Tim GJ Rudner, Chia-Man Hung, Philip HS Torr, Jakob Foerster, and Shimon Whiteson. "The StarCraft Multi-Agent Challenge." arXiv preprint arXiv:1902.04043, 2019.
- John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. "Proximal Policy Optimization Algorithms." arXiv preprint arXiv:1707.06347, 2017.
- Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinícius Flores Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. "Value-Decomposition Networks for Cooperative Multi-Agent Learning Based on Team Reward." Conference on Autonomous Agents and Multi-Agent Systems, 2018.
- Tabish Rashid, Mikayel Samvelyan, Christian Schroeder, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. "Qmix: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning." International Conference on Machine Learning, 2018.
- Ming Tan. "Multi-Agent Reinforcement Learning: Independent vs. Cooperative Agents." International Conference on Machine Learning, 1993.
- Chao Yu, Akash Velu, Eugene Vinitsky, Yu Wang, Alexandre Bayen, and Yi Wu. "The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games." arXiv preprint arXiv:2103.01955, 2021.