The Multi-Robot Warehouse and Level-Based Foraging Environments

I believe every Multi-Agent Reinforcement Learning (MARL) researcher can relate with one thing: the perpetual search for a suitable, fast, and highly-polished environment.
MARL lacks the environments of single-agent RL, which have been developed and polished by companies with significant resources (e.g. OpenAI's Gym, or MuJoCo). Instead, many of the current MARL environments have been developed by individual researchers and therefore are more limited. We introduce the open-source Multi-Robot Warehouse (RWARE) and Level-Based Foraging (LBF) environments, which both aim to be a solid addition to the arsenal of a MARL researcher. Many aspects in RWARE and LBF are configurable to allow for different assumptions, and the code is optimised for efficient MARL training. We also describe Shared Experience Actor-Critic (SEAC) [1], a new MARL algorithm which achieves state-of-the-art performance in these environments.
Multi-Robot Warehouse (RWARE)

The multi-robot warehouse (RWARE) environment simulates a warehouse with robots moving and delivering requested goods. We based the simulator on real-world applications, in which robots pick-up shelves and deliver them to a workstation. Humans access the content of a shelf, and then robots can return them to empty shelf locations. The image on the right helps visualise how the robots might look like in real-life.
The environment is configurable: it allows for different sizes (difficulty), number of agents, communication capabilities, and reward settings (cooperative/individual). Of course, the parameters used in each experiment must be clearly reported to allow for fair comparisons between algorithms.
Environment Details
Below, we give detailed information about the dynamics of RWARE.
Action Space
In this simulation, robots have the following discrete action space:
\[ A=\{\text{Turn Left, Turn Right, Forward, Load/Unload Shelf}\} \]
The first four actions allow each robot only to rotate and move forward. Loading/Unloading only works when an agent is beneath a shelf on one of the predesignated locations.
Observation Space
The observation of an agent is partially observable and consists of a 3x3 (configurable) square centred on the agent. Inside this limited grid, all entities are observable:
- The location, the rotation and whether the agent is carrying a shelf.
- The location and rotation of other robots.
- Shelves and whether they are currently in the request queue.
Dynamics: Collisions
The dynamics of the environment are also of particular interest. Like a real, 3-dimensional warehouse, the robots can move beneath the shelves. Of course, when the robots are loaded, they must use the corridors, avoiding any standing shelves.
Any collisions are resolved in a way that allows for maximum mobility. When two or more agents attempt to move to the same location, we prioritise the one that also blocks others. Otherwise, the selection is done arbitrarily. The visuals below demonstrate the resolution of various collisions.
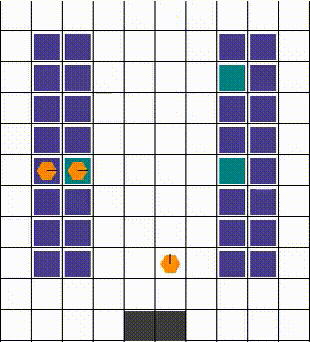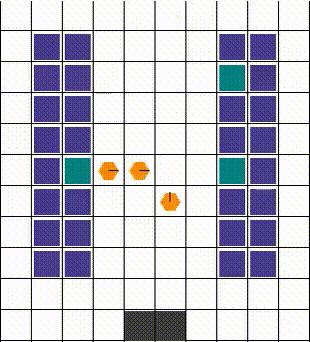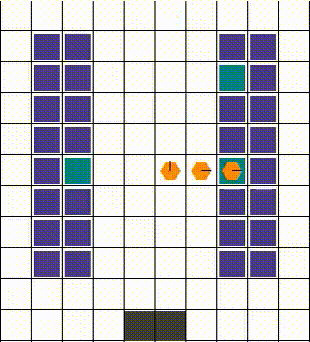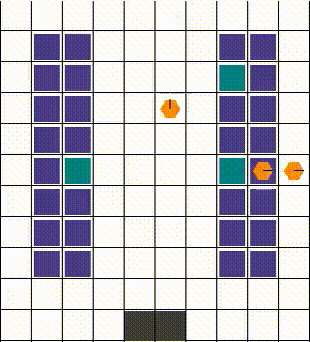
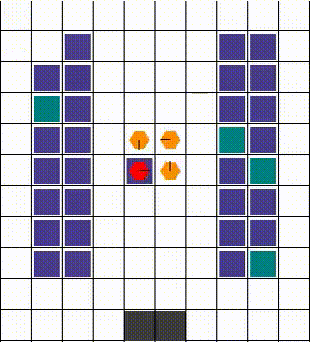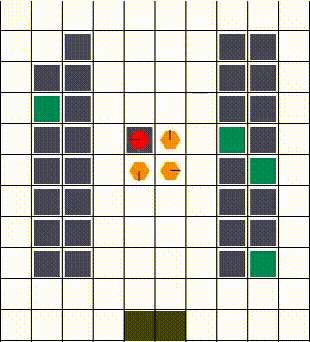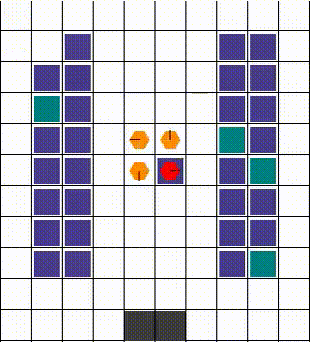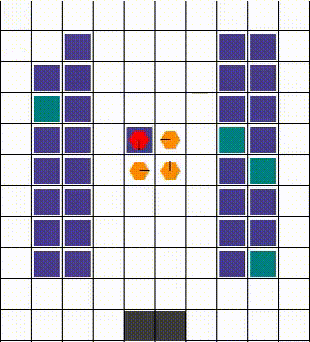
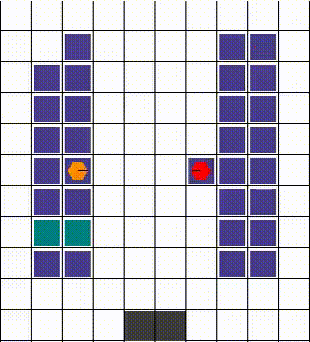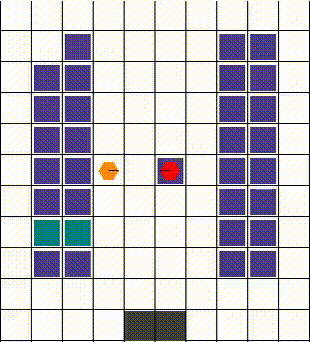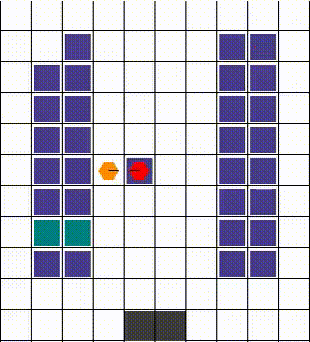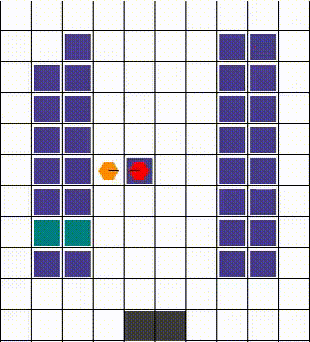
Rewards
At each time a set number of shelves R is requested. When a requested shelf is brought to a goal location, another shelf is uniformly sampled and added to the current requests. Agents are rewarded for successfully delivering a requested shelf to a goal location, with a reward of 1. A significant challenge in these environments is for agents to deliver requested shelves but also finding an empty location to return the previously delivered shelf. Having multiple steps between deliveries leads a very sparse reward signal.
Since this is a task that no agent can benefit at the expense of another, as a performance metric, we use the sum of the undiscounted returns of all the agents.
The multi-robot warehouse task is parameterised by:
- The size of the warehouse which is preset to either tiny (10x11), small (10x20), medium (16x20), or large (16x29).
- The number of agents.
- The number of requested shelves R. By default \(R = N\), but easy and hard variations of the environment use \(R=2N\) and \(R = \frac{N}{2}\), respectively.
Note that R directly affects the difficulty of the environment. A small R, especially on a larger grid, dramatically affects the sparsity of the reward and thus exploration: randomly bringing the correct shelf becomes increasingly improbable.
Download & Installation
The code lives in a GitHub repository. Assuming you have Git and Python3 (preferably on a virtual environment: venv or Anaconda) installed, you can download and install it using
git clone git@github.com:uoe-agents/robotic-warehouse.git
cd robotic-warehouse
pip install -e .Getting Started
RWARE was designed to be compatible with Open AI's Gym framework.
Creating the environment is done exactly as one would create a Gym environment:
import gym
import robootic_warehouse
env = gym.make("rware-tiny-2ag-v1")The number of agents, the observation space, and the action space are accessed using:
env.n_agents # 2
env.action_space # Tuple(Discrete(5), Discrete(5))
env.observation_space # Tuple(Box(XX,), Box(XX,))The returned spaces are from the Gym library (gym.spaces)
Each element of the tuple corresponds to an agent, meaning that len(env.action_space) == env.n_agents and len(env.observation_space) == env.n_agents are always true.
The reset and step functions again are identical to Gym:
obs = env.reset() # a tuple of observations
actions = env.action_space.sample() # the action space can be sampled
print(actions) # (1, 0)
n_obs, reward, done, info = env.step(actions)
print(done) # [False, False]
print(reward) # [0.0, 0.0]
which leaves as to the only difference with Gym: the rewards and the done flag are lists, and each element corresponds to the respective agent.
Finally, the environment can be rendered for debugging purposes:
env.render()
and should be closed before terminating:
env.close()
Environment Naming Scheme and Other Settings
The only part we left unexplained is the naming scheme.
"rware-tiny-2ag-v1" seems cryptic in the beginning, but it is not actually complicated. Every name always starts with rware. Next, the map size is appended as -tiny, -small, -medium, or -large. The number of robots in the map is selected as Xag with X being a number larger than one (e.g. -4ag for 4 agents). A difficulty modifier is optionally appended in the form of -easy or -hard, making requested shelves twice or half the number of agents (see section Rewards). Finally -v1 is the version as required by OpenAI Gym. In the time of writing all environments are v1, but we will increase it during changes or bugfixes.
Of course, more settings are available, but have to be changed during environment creation. For example:
env = gym.make("rware-tiny-2ag-v1", sensor_range=3, request_queue_size=6)
A detailed explanation of all parameters can be found here.
Level-Based Foraging
Another environment, with similarities to RWARE, is the Level-Based Foraring (LBF) (code here). This environment is a mixed cooperative-competitive game, which focuses on the coordination of the agents involved. Agents navigate a grid world and collect food by cooperating with other agents if needed.
More specifically, agents are placed in the grid world, and each is assigned a level. Food is also randomly scattered, each having a level on its own. Agents can navigate the environment and can attempt to collect food placed next to them. The collection of food is successful only if the sum of the levels of the agents involved in loading is equal to or higher than the level of the food. Finally, agents are given a reward equal to the level of the food they helped collect, divided by their contribution (their level) and the sum food levels in the episode. The figures below show two states of the game, one that requires cooperation, and one more competitive.
While it may appear simple, this is a very challenging environment, requiring the cooperation of multiple agents while being competitive at the same time. In addition, the discount factor also necessitates speed for the maximisation of rewards. Each agent is only rewarded if it participates in the collection of food, and it has to balance between collecting low-levelled food on his own or cooperating in acquiring higher rewards. In situations with three or more agents, highly strategic decisions can be required, involving agents needing to choose with whom to cooperate. Another significant difficulty for RL algorithms is the sparsity of rewards, which causes slower learning.
Like RWARE, LBF is based on OpenAI's RL framework, with modifications for the multi-agent domain. The efficient implementation allows for thousands of simulation steps per second on a single thread, while the rendering capabilities allows humans to visualise agent actions. Our implementation can support different grid sizes or agent/food count. Also, game variants are implemented, such as cooperative mode (agents always need to cooperate) and shared reward (all agents always get the same reward), which is attractive as a credit assignment problem.
You can install LBF using:
pip install lbforaging
And use it in a very similar manner to RWARE:
import gym
import lbforaging
env = gym.make("Foraging-8x8-2p-1f-v0")
actions = env.action_space.sample()
n_obs, reward, done, info = env.step(actions)
Baselines: A2C and SEAC
One of the most useful things is that the easiest variations of these environments can be solved quite fast: a few minutes for LBF and a couple of hours for RWARE. A fast learning time allows for fast debugging, iteration, and preliminary results before scaling up to harder environments. We found that independent A2C is one of the most straightforward algorithms that perform well in the simpler RWARE and LBF tasks.
In our study [2] you will notice that, unexpectedly, independent learning appears to be the more reliable candidates, despite it being a multi-agent problem. Existing MARL algorithms do not appear to be as efficient at solving these environments (sparse rewards, less coordination, and more). In SEAC [1], we take advantage of the multi-agent nature of the problem and make use of the exploration of all agents to achieve state-of-the-art performance.
SEAC works by sharing experiences between agents, while still allowing individual agents to have distinct policies. As the diagram below shows, when training a policy, we use not only the experience collected by the agent being trained, but also by other agents. Since the algorithm is on-policy, experience of others is re-weighted using importance sampling before used to compute the gradients.

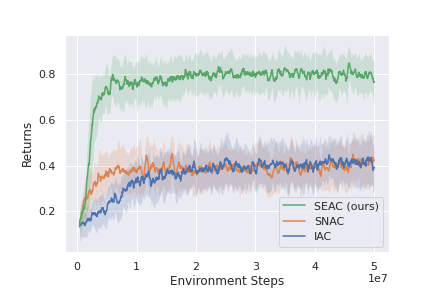
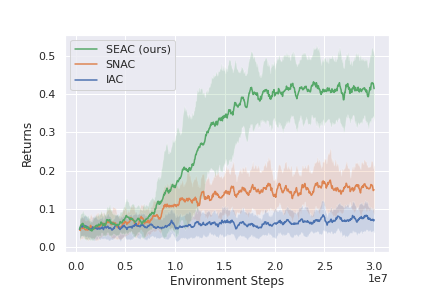
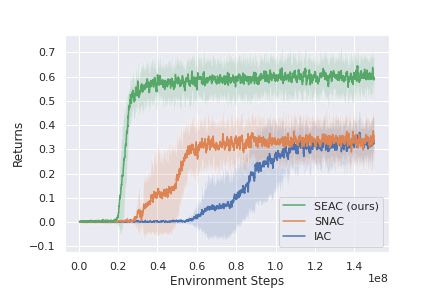
This method shows state-of-the-art results in both RWARE and LBF, and could be used as a strong baseline when developing new ideas that work in these environments. Below are some of the results presented in the original paper for RWARE and LBF. Note that IAC represents independent learning (each agents independently tries to learn the environment) and SNAC is sharing a single network between all agents and learns a single policy from the experience of all agents.
LBF 10x10, 3ag, 3 foods
LBF 15x15, 3ag, 4 foods
LBF 8x8, 2ag, 2 foods (coop)
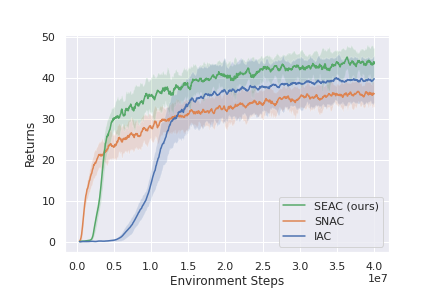
RWARE 10x11, 4ag
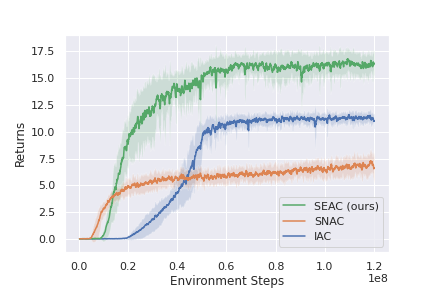
RWARE 10x11, 2ag (hard)
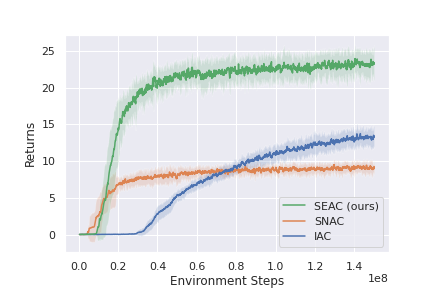
RWARE 10x20, 4ag
More results and a detailed description of SEAC can be found in the paper: https://arxiv.org/pdf/2006.07169.pdf. Hopefully, the environments along the baselines provided offer a challenging environment for further research in MARL.
References
- Filippos Christianos, Lukas Schäfer, Stefano V. Albrecht. "Shared Experience Actor-Critic for Multi-Agent Reinforcement Learning." In: Conference on Neural Information Processing Systems, 2020.
- Papoudakis Georgios, Christianos Filippos, Lukas Schäfer, and Stefano V. Albrecht. "Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks." In: Conference on Neural Information Processing Systems, Datasets and Benchmarks Track, 2021.