Research
The group focuses on the research topics below. Our overview paper provides a summary of ongoing research in the group. For more information about projects, see People and Publications.
Multi-Agent Reinforcement Learning

Decentralised learning of coordinated agent policies and inter-agent communication in multi-agent systems is a long-standing open problem. We tackle this problem by developing algorithms for multi-agent deep reinforcement learning, in which multiple agents learn how to communicate and (inter-)act optimally to achieve their specified goals. While deep RL has enabled scalability to large state spaces, the goal of multi-agent RL is to enable efficient scalability in the number of agents where the joint decision space would otherwise be intractable for centralised approaches.
Recent publications:
Pareto Actor-Critic for Equilibrium Selection in Multi-Agent Reinforcement Learning
Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks
Shared Experience Actor-Critic for Multi-Agent Reinforcement Learning
Decision Making and Modelling Other Agents
Our long-term goal is to create autonomous agents capable of robust goal-directed interaction with other agents, with a particular focus on problems of "ad-hoc" teamwork requiring fast and effective adaptation without opportunities for prior coordination between agents. We develop algorithms enabling an agent to reason about the capabilities, behaviours, and composition of other agents from limited observations, and to use such inferences in combination with reinforcement learning and planning techniques for effective decision making.
Recent publications:
A General Learning Framework for Open Ad Hoc Teamwork Using Graph-based Policy Learning
Generating Teammates for Training Robust Ad Hoc Teamwork Agents via Best-Response Diversity
Agent Modelling under Partial Observability for Deep Reinforcement Learning
Autonomous Driving in Urban Environments
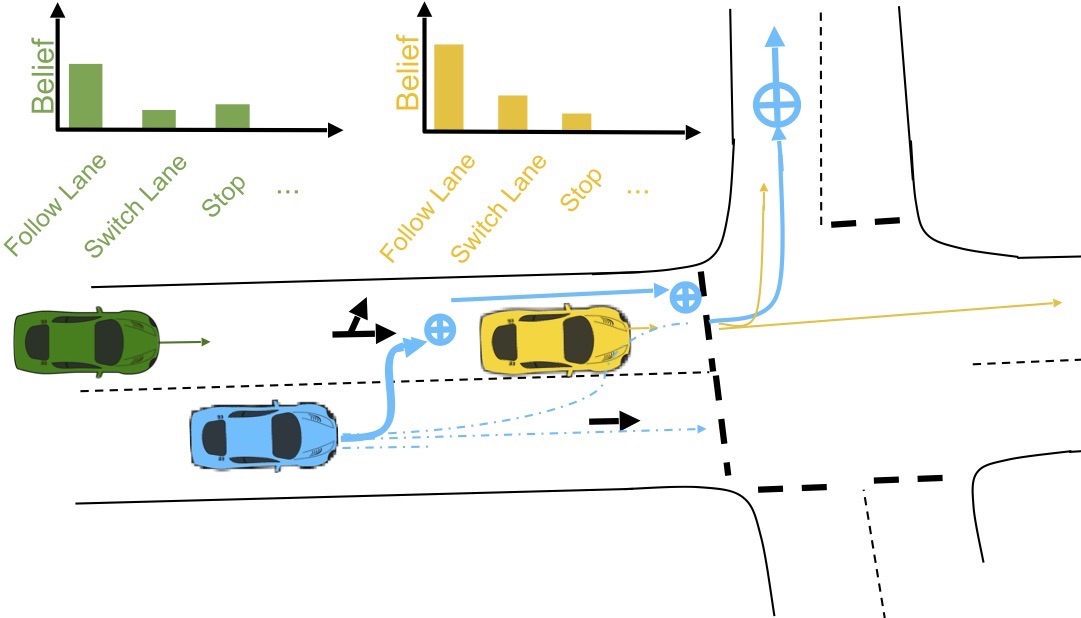
We develop algorithms for autonomous driving in challenging urban environments, enabling autonomous vehicles to make fast, robust and safe decisions by reasoning about the actions and intent of other actors in the environment. Research questions include: how to perform complex state estimation; how to efficiently reason about intent from limited data; how to compute robust plans with specified safety-compliance under conditions of dynamic, uncertain observations and limited compute budget. Work in collaboration with Five AI (Bosch).
Recent publications:
Verifiable Goal Recognition for Autonomous Driving with Occlusions
Planning with Occluded Traffic Agents using Bi-Level Variational Occlusion Models
Interpretable Goal-based Prediction and Planning for Autonomous Driving
Quantum-Secure Authentication and Key Agreement

Classical protocols for authentication and key establishment relying on public-key cryptography are known to be vulnerable to quantum computing. We develop a novel, quantum-resistant approach to authentication and key agreement which is based on the complexity of interaction in multi-agent systems, supporting mutual and group authentication as well as forward secrecy. We leverage recent progress in generative adversarial training and multi-agent reinforcement learning to maximise the security of our system against intruders and modelling attacks.
Recent publications:
Towards Quantum-Secure Authentication and Key Agreement via Abstract Multi-Agent Interaction
Stabilizing Generative Adversarial Networks: A Survey